图像分割之k-means聚类分割bb

k-means聚类原理
k-means聚类是一种无监督学习的聚类算法,它的目的是将数据集中的样本划分成若干个类别,使得同一类别内的样本相似度高,而不同类别之间的样本相似度低。其目标是将数据点划分为k个类簇,找到每个簇的中心并使其度量最小化。
此外,K-means算法有一些优点,如简单易懂、计算速度快,适合处理大数据集。但它也有一些缺点,比如需要预先指定簇的数量K,对初始聚类中心的选择敏感,可能收敛到局部最优而非全局最优解,对于非凸数据集和噪声数据敏感。
在实际应用中,K-means算法广泛应用于市场细分、图像分割、社交网络分析等领域。本文主要将其应用于图像分割领域。
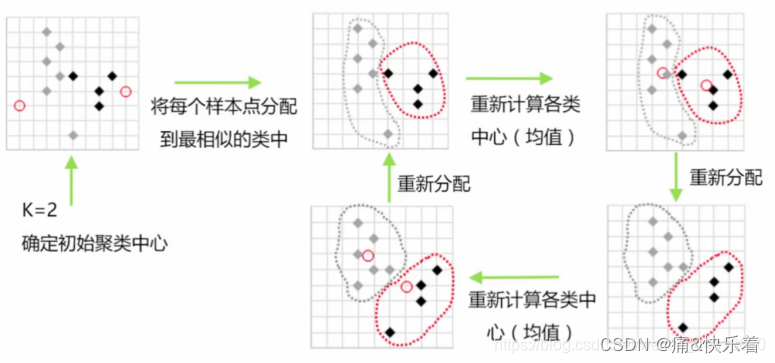
k-means基本思路
通过计算相似度(默认欧氏距离),将相似度大的样本聚集到同一个类别,k表示聚成k个类别,means表示每个类别的聚类中心点是通过簇中所有样本点的均值得到。
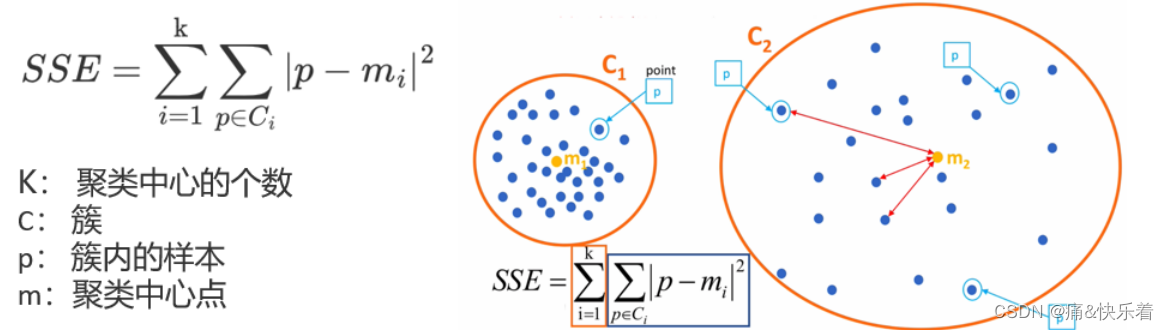
聚类效果评估
聚类的效果可采用误差平方和SSE进行评价,SSE值越小,表示数据点越接近它们的中心点,聚类效果越好。
k-means聚类算法流程
下面是K-Means聚类算法的分析流程,步骤如下:
第一步,确定K值,即将数据集聚集成K个类簇或小组。第二步,从数据集中随机选择K个数据点作为质心(Centroid)或数据中心。第三步,分别计算每个点到每个质心之间的距离,并将每个点划分到离最近质心的小组,跟定了那个质心。第四步,当每个质心都聚集了一些点后,重新定义算法选出新的质心。第五步,比较新的质心和老的质心,如果新质心和老质心之间的距离小于某一个阈值,则表示重新计算的质心位置变化不大,收敛稳定,则认为聚类已经达到了期望的结果,算法终止。第六步,如果新的质心和老的质心变化很大,即距离大于阈值,则继续迭代执行第三步到第五步,直到算法终止。
对于图像分割任务,需要在第一步之前将图像reshape为m*n行、p列的矩阵,这样每一行就是一个p维数据点。通过以上聚类算法,得到最终的聚类结果,最后再将结果reshape为原始图像的大小即可。
Loading...