数仓分层建模


一、数据指标建设过程
为保证数据尽早产生数据价值,数仓的建设除了前期需要基于业务板块和业务过程的顶层设计外,剩余的需要基于业务需求,反哺进行数据的建设和迭代优化。
对于一个具体的数据需求建设,需要以下几个步骤。虚线框中的部分则就是数仓建设的重点。
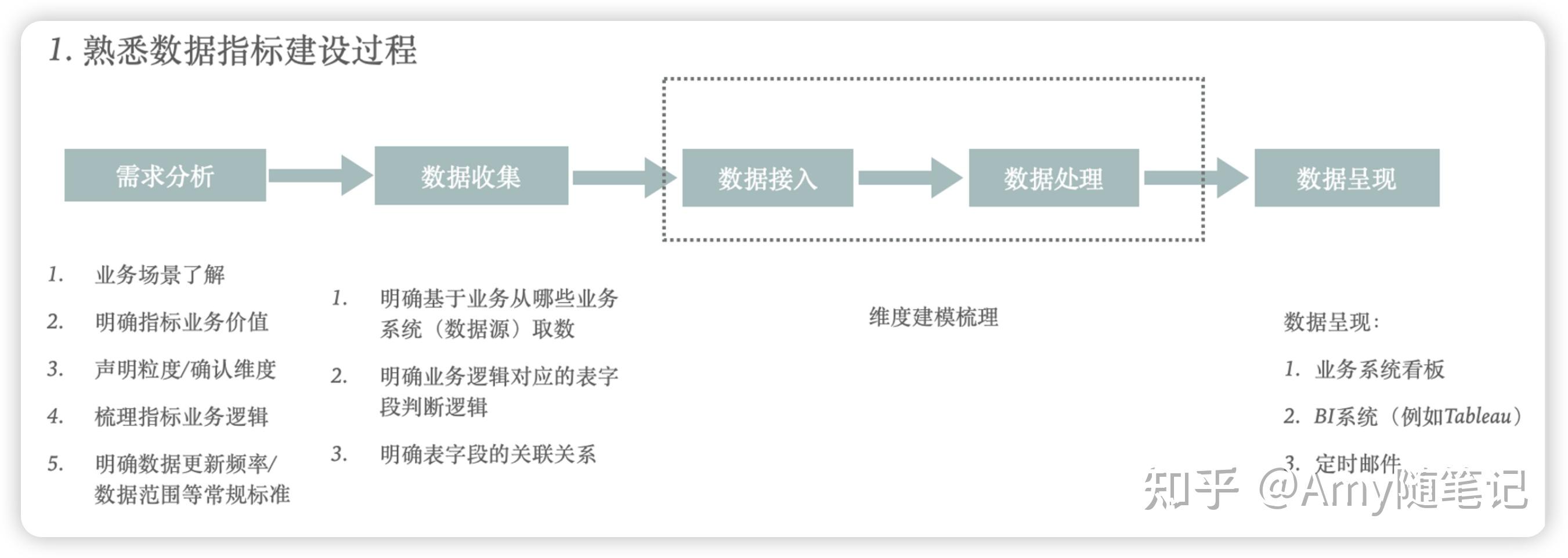
二、数仓平台建设
数据平台建设,总结来讲就是对数据采、存、管、用的实践过程:
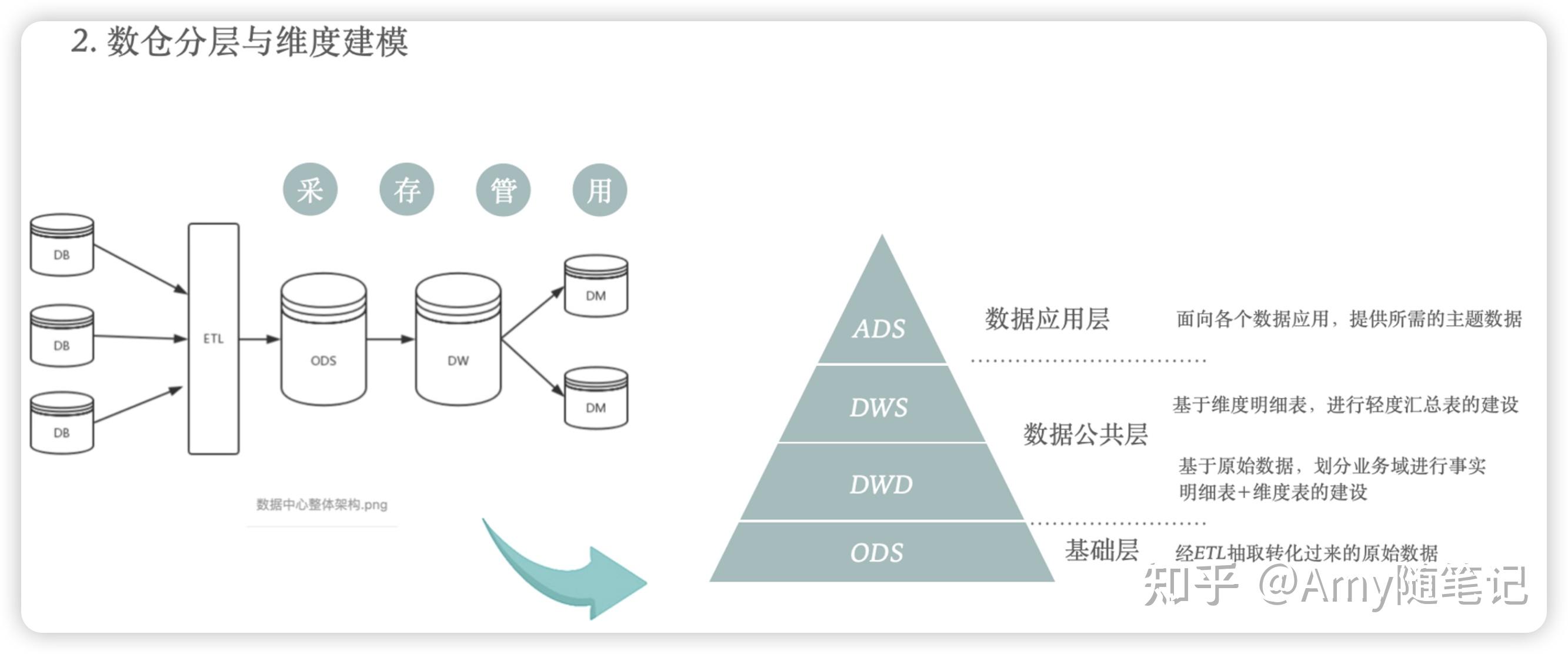
采:就是将数据从各个业务系统、EXCEL、第三方系统等不同数据源、不同格式的数据采集过来,经过ETL过程进行增量或存量存储
存:基于数仓星型模型或者雪花模型的设计方法,通过维度表和事实表,建设DWD、DWS、ADS层的数据存储
管:即数据资产的管理,包括元数据管理、数据血缘关系管理、数据标准规范管理等
用:作为数据平台,为各个数据应用方提供所需的数据,用数据驱动业务价值
而数仓建设就是其中的核心。数仓的建模或者分层,其实都是为了更好的去组织、管理、维护数据。优秀的分层设计能够让整个数据体系更容易理解和使用。
三、维度建模
数仓分层用到的主要思路就是维度建模。维度建模主要分为星型模型、雪花模型、星座模型。
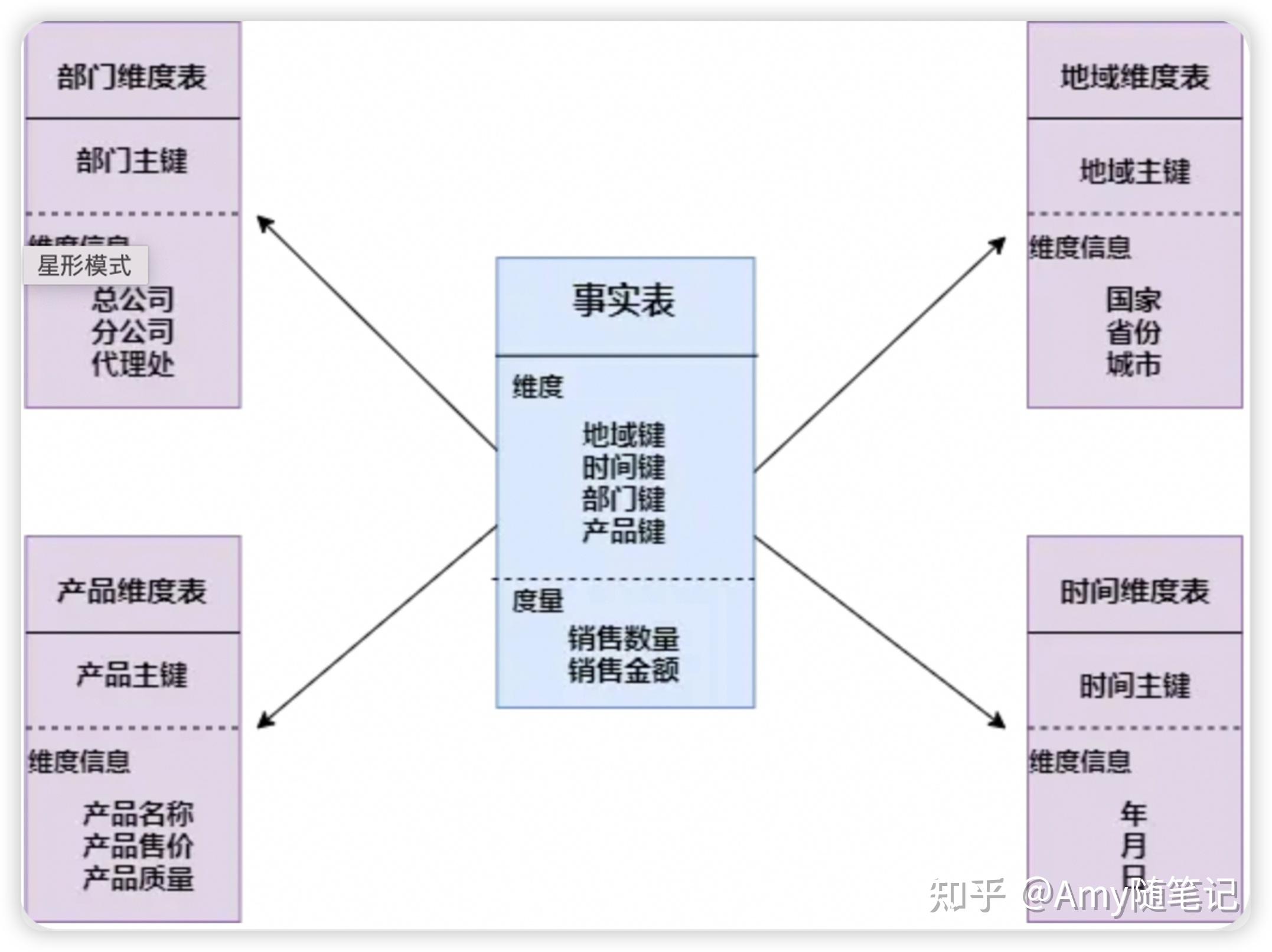
- 星型模型:以事实表为中心,所有的维度表直接连在事实表上,最简单最常用的一种:
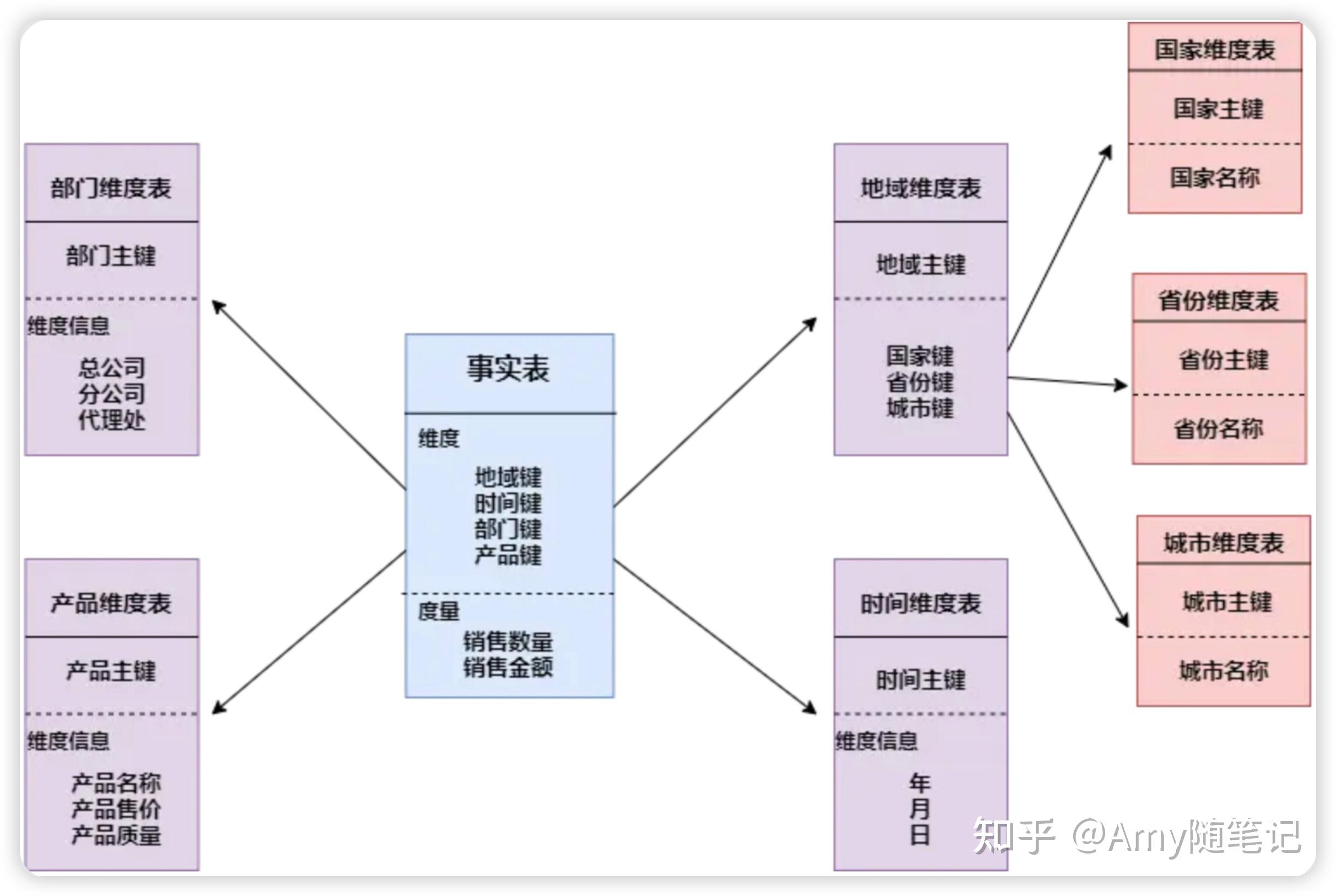
2. 雪花模式:雪花模式的维度表可以拥有其他的维度表:
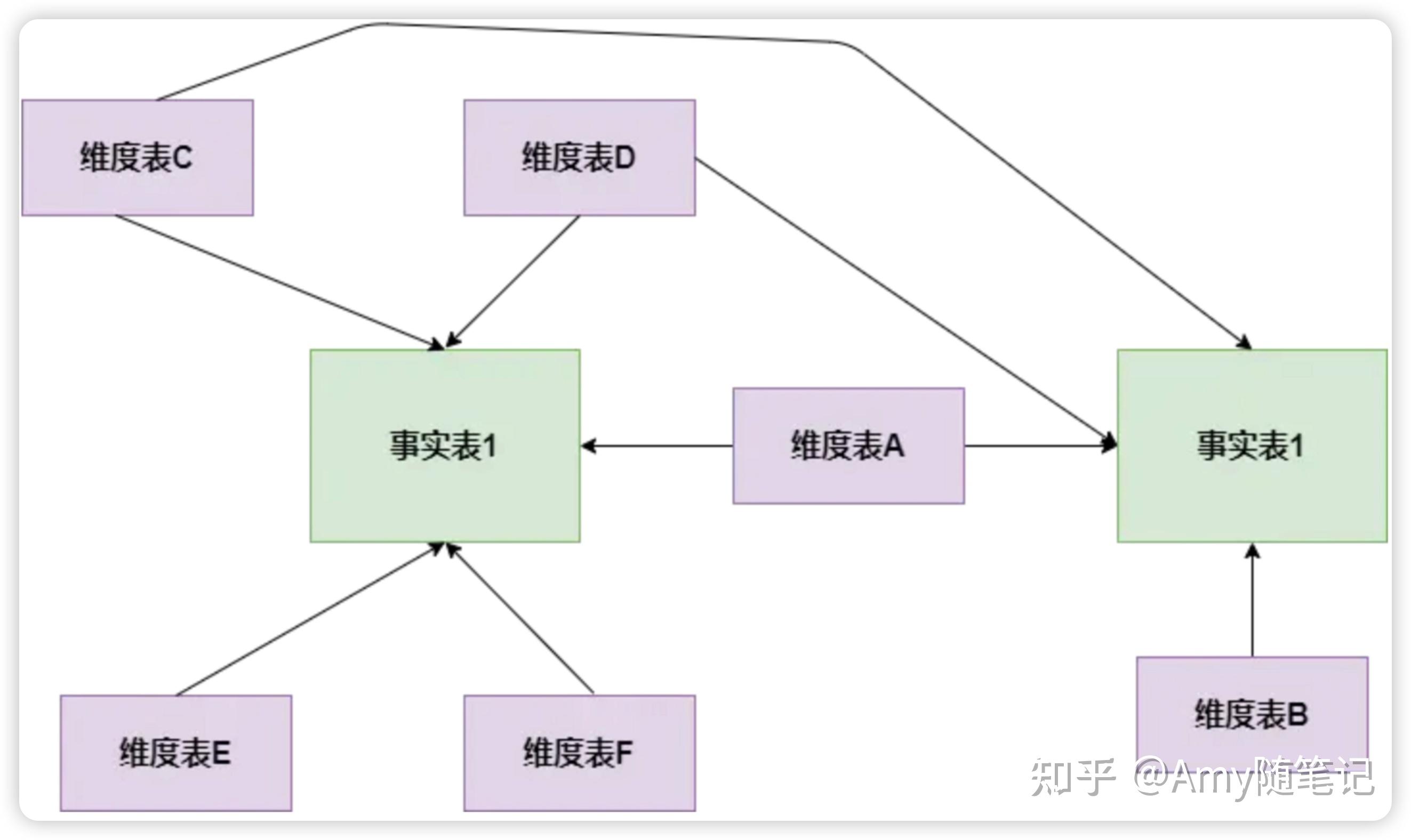
3. 星座模式:基于多张事实表,而且共享维度信息,即事实表之间可以共享某些维度表:
四、数仓三层架构
ODS层
全称operational data store, 操作数据层,也称为贴源层。经过ETL抽取转化加载过来的原始数据,目的也是为了备份和隔离不同数据源的数据。这一层因为不做数据处理,所以和数据源数据结构相同,因此该层的数据结构和各业务系统是一样的,是符合业务数据库3NF设计原则的。
数据库三范式设计,目的是为了减少数据冗余,存储更合理。这里可以作为简单的了解,方便理解业务系统数据。单表数据冗余多表数据查询效率
ODS层的数据,根据不同公司的使用习惯和处理方式,有时也会进行一些简单的数据处理,例如数据异常值、空值、命名规范、去重等处理,有时也可能为了数据溯源,不做任何处理,等到DW层再做处理也是可以的。
DW层
DW层是数据仓库的核心,从ODS层中获得的数据按照主题、业务域建立各种数据模型。
DW层又细分为数据明细层DWD 、轻度汇总层DWS和维表层DIM。
- DWD层:
全称data warehourse detail, 也称为数据明细层。DWD层要做的就是将数据整合、规范化、脏数据、垃圾数据、规范不一致的、状态定义不一致的、命名不规范的数据都会被处理。然后加工成面向数仓的基础明细表,这个时候可以加工一些面向分析的大宽表。
DWD层应该是覆盖所有系统的、完整的、干净的、具有一致性的数据层。在DWD层会根据维度模型,设计事实表和维度表,也就是说DWD层是一个非常规范的、高质量的、可信的数据明细层。
2. DWS层:
data warehouse service,基于数据明细表,进行轻度汇总,建设公共的指标汇总表。可以按照业务域划分,例如内容,订单,用户等业务域,生成字段比较多的宽表,用于后续的业务查询,OLAP分析,数据分析等。
3. DIM层:
全称Dimension,维表层,就是大量维表构成的,为了统一管理这些维度表,我们就需要建设公共维度层。
维度指的是观察事物的角度,提供某一业务过程事件涉及用什么过滤和分类的描述属性。
比如,"小王早上在咖啡店花费9.9元钱购买了一杯咖啡",那么这里的时间维度就是【早上】,地点维度【咖啡店】,商品维度【咖啡】
所以可以看出,维度表包含了业务过程记录的业务过程度量的上下文和环境。维度表都包含单一的主键列,也是查询的约束条件(where)、分组条件(group)、排序(order)的标签。
每个维度表都包含单一的主键列。维度表的主键可以作为与之关联的任何事实表(DWD、DWS)的外键。 维度表通常比较宽,是扁平型非规范表,包含大量的低粒度的文本属性。例如customer(客户表)、goods(商品表)、d_time(时间表)这些都属于维度表,这些表都有一个唯一的主键,然后在表中存放了详细的数据信息。
ADS层
application data store,应用数据层,面向各个数据应用提供定制化的指标汇总或数据。一般会放在ES,MYSQL,Redis等系统供线上系统使用,也可以放在Hive中供数据分析和数据挖掘使用,或者使用一下其他的大数据工具进行存储和使用。
五、数仓四层架构
对于数仓分层架构,一般就是三层建设。随着业务的发展,就需要对用户进行精细化运营,提供更加精准和个性化的服务。这时候就需要增加TDM层,变成四层架构。
TDM层
Tag data store,标签数据层。面向对象,把跨业务板块、跨数据域的特定对象数据进行整合,形成对象的全域标签数据体系,方便深度的分析、挖掘和应用。这一层的特点就是有大量的算法标签,大数据的智能化也体现在这一层。
对于标签的分类,签按照产生和计算方式的不同可分为属性标签,统计标签,算法标签,关联标签。
属性标签
对象本身的性质就是属性标签,例如用户画像的时候打到用户身上的标签。
统计标签
对象在业务过程中产生的原子指标,通过不同的计算方法可以生成统计标签。
算法标签
对象在多个业务过程中的特征规律通过一定的算法产出的标签。
关联标签
对象在特定的业务过程会和其他对象关联,关联对象的标签也可以打在主对象上。
六、分层建设的作用
开始我们提到,数仓的建模或者分层,其实都是为了更好的去组织、管理、维护数据。越靠上的层次,对应用越友好,比如ADS层,基本是完全为应用设计, 越上层的聚合程度越高,可理解程度就越低。
分层是为了解决 ETL 任务及工作流的组织、数据的流向、读写权限的控制、不同需求的满足等各类问题,不能为了分层而分层。为了解决这些问题,分层仅仅是手段而已。
总结一下,分层建设有以下作用和优点:
1. 隔离原始数据
后期统计和真实数据解除耦合,也就是这边备份了原始数据,不影响原始数据的资源。
2. 清晰数据结构体系
将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。这样在使用表的时候能更方便的定位和理解;也使得开发、维护的成本降低;
3. 数据查询效率高:
分层架构就是利用大数据的技术,通过预计算+占空间这些看上去的缺点,得到效率高的优点。相当于就是把中间数据先提前存储好,然后后面需要使用这些中间数据直接利用这些中间数据即可,加快速度查询效率
4. 数据复用性提高。
分层后,在中间层会存储很多中间数据,这些数据可以给不同的上层使用,这就达到了数据复用。
5. 数据血缘追踪
由于最终给业务呈现的是一个能直接使用的业务表,但是表的数据来源有很多,如果有一张来源表出问题了,我们希望能够快速准确的定位到问题,并清楚它的影响范围,从而及时给到业务方反馈,从而将损失降到最低。
6. 统一数据口径
通过数据分层提供统一的数据出口,统一对外输出的数据口径。
Loading...