可观测性黄金三角
今天,市面上的监控系统可以说是百花齐放了,从 Google Dapper 再到后面各种开源的监控系统,例如 ZipKin/Pinpoint/ Apache Skywalking / OpenTelemetry / Elasticsearch / Prometheus 等等,无一不是围绕着 Metrics / Tracing / Logging 三种数据中的一种或者多种来进行设计实现的。本文旨在帮助读者更好地理解这三种数据各自的特点以及三者之间存在的关系。
介绍

Metrics
- 一组描述过程或者活动的数据
- 跟随着时间变化的时序数据
- 可聚合的 KV 数据
- 可压缩、存储、处理、检索
Metrics 一般是用来计算 Events 发生数量的数据集,这些数据通常具有原子性,且可以聚合。从操作系统到应用程序,任何事物都会产生 Metrics 数据,这些数据可以用来度量操作系统或应用程序是否健康,或者是用以计算一段时间内请求的平均延时。由于目前并没有 Metrics 采集的标准 API,所以不同的监控系统在收集 Metrics 数据时采取的手段也可能不一样,但大部分无非都是通过 PUSH 到中心 Collector 方式采集 Metrics(比如各种 Agent 采集器,Telegraf 等);又或者是中心 Collector 通过 PULL 的方式去主动获取 Metrics(比如 Prometheus)。最重要的是可以将采集到的 Metrics 数据与对应的系统或应用程序相关联,通过图表或其他方式直观展示,使得这些 Metrics 更具有价值。

Logging
- 记录离散 Events
Logging 描述的是一些列离散事件,在缺乏有力的监控系统时,Logging 数据通常是工程师在定位生产问题时最直接的手段。如果说 Metrics 可以告诉你系统或者应用程序出现问题,那么 Logging 就可以告诉你为什么会出现问题。关于日志的采集现在也有很多方法,比如:filebeat, fluented, loki 等。

Tracing
- 通常是记录应用程序操作的数据
- 一次请求的完整生命周期
- 分布式系统中一次请求经历过多个服务产生操作的数据(Spans)
Tracing 是通过有向无环图的方式记录在分布式系统中发生的 Events 之间的因果关系。云原生场景下,多个服务之间或多或少存在着依赖关系,一次 Tracing 通常会经过多个服务(Span),甚至在高度复杂的分布式系统中,一次 Tracing 包含数以万计的 Span 也是可能存在的。再者,Tracing 更多的是关注这种端到端系统之间的联系,基于该需求,分布式追踪系统应运而生。
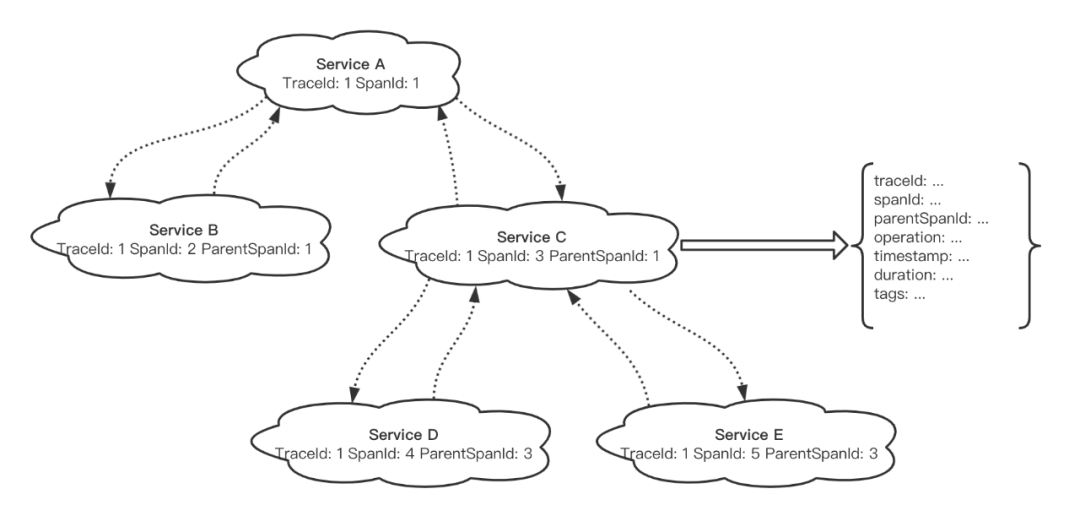

三者之间的关系
- 在一次用户请求发生时,可以记录这次请求延时、请求发生的次数等 Metrics 数据,用以量化展示。
- 同时也可以记录这次请求发生时经过多个服务的 Tracing 数据,这样可以更加直观地看到请求在各个服务中到底经历了什么。
- 当然还可以在发生错误时记录详细的 Logging 数据(除非有必要,否则推荐只在发生错误时记录日志)。
根据以上几点,我们很容易发现 Metrics/Tracing/Logging 这三种数据之间是存在着某种联系的。
下面,通过 Peter Bourgon 提供的一张维恩图,我们再来深入了解一下三者之间的关系:
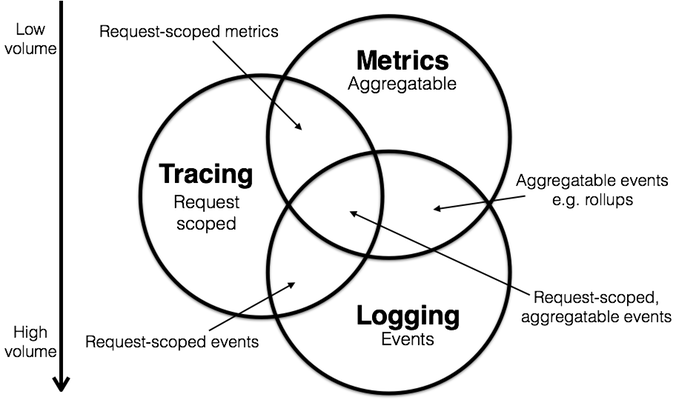
如上图所示,可以看出三种数据之间是有一定冗余的,并且他们产生的存储需求也有很大不同,所以在选择采集何种数据时,就得根据系统的复杂程度来判断。简而言之:
- Metrics 倾向于更节省资源。
- Logging 倾向于无限增加,会频繁超出预期的容量(当然可以通过告警的方式去预防)。
- 而 Tracing 数据则介于两者之间。
Loading...